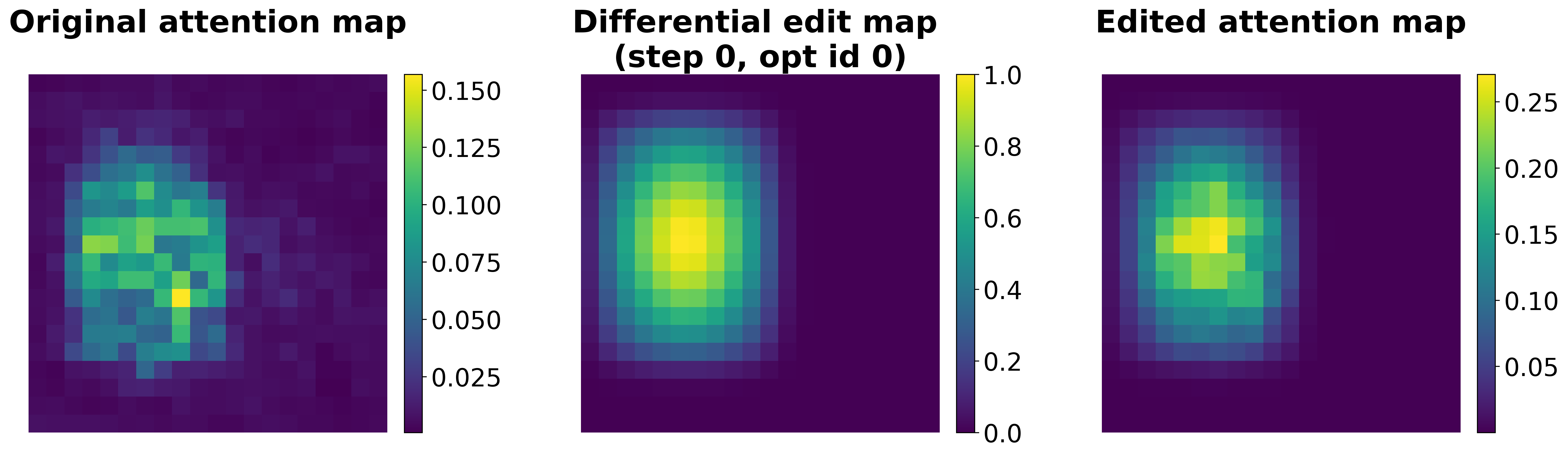
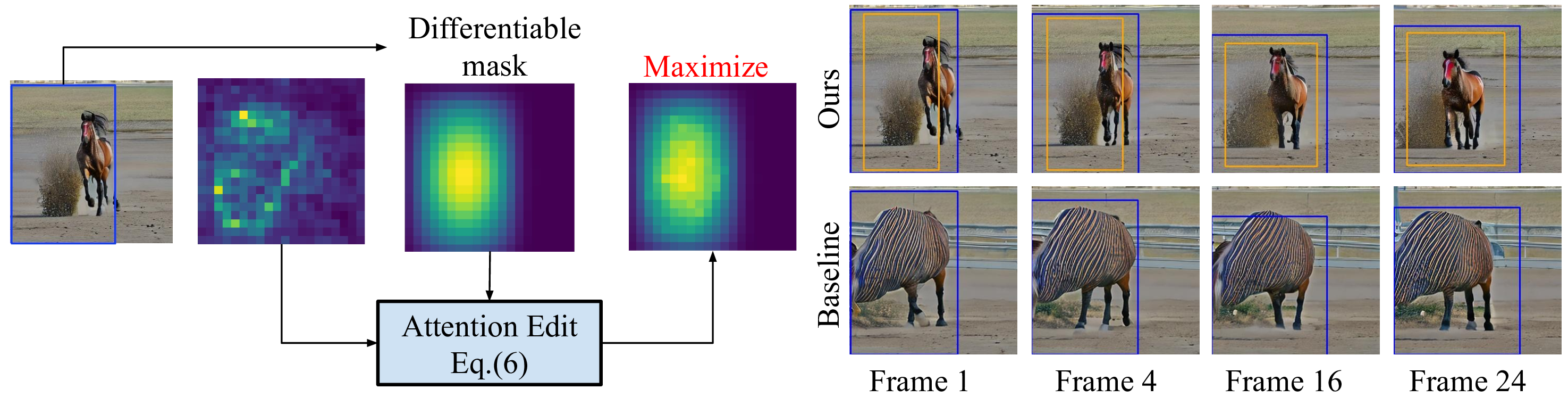
In short: Slightly adjusting user-provided boxes to align with internal attention maps significantly improve the quality of generations.
Abstract
With the recent drastic advancements in text-to-video diffusion models, controlling their generations has drawn interest. A popular way for control is through bounding boxes or layouts. However, enforcing adherence to these control inputs is still an open problem. In this work, we show that by slightly adjusting user-provided bounding boxes we can improve both the quality of generations and the adherence to the control inputs. This is achieved by simply optimizing the bounding boxes to better align with the internal attention maps of the video diffusion model while carefully balancing the focus on foreground and background. In a sense, we are modifying the bounding boxes to be at places where the model is familiar with. Surprisingly, we find that even with small modifications, the quality of generations can vary significantly. To do so, we propose a smooth mask to make the bounding box position differentiable and an attention-maximization objective that we use to alter the bounding boxes. We conduct thorough experiments, including a user study to validate the effectiveness of our method.